
Evaluation
Evaluation for LLM
Evaluation
1. Why is evaluation necessary? 🤔
LLMs can produce different results even with the same input.
Therefore, LLM applications require LLM quality evaluation in addition to traditional functional QA.
Examples of LLM evaluation criteria include:
- Accuracy: Does the answer match the facts?
- Relevance: Is it directly related to the question?
- Safety: Are there no biased or harmful expressions?
You can also define evaluation criteria tailored to your use case:
- Translation Quality: Is it translated appropriately for the context?
- Plan Creation: Is the plan generated realistically?
Through these evaluation results, you can select the optimal combination of models, prompts, and parameter settings, and continuously improve service quality.
2. How does evaluate? 🤩
Traditionally, there's Human Evaluation where people directly review results and assign scores or rankings.
However, this method is time-consuming and costly, and difficult to execute regularly due to competing work priorities.
To overcome this, our platform adopts the LLM-as-a-Judge approach to perform Automated Evaluation.
This ensures scalability and efficiency in evaluation, enabling regular monitoring of LLM quality.
3. Why should you use Eval? 🙋♀️
(1) Easy to get started.
- You can evaluate Input/Output immediately without complex setup.
(Supports direct data input or observability tool integration) - Quickly receive evaluation results and compare them at a glance on the dashboard.
- Team collaboration is possible through the console.
(Integrated with existing GIP Workspace units)
(2) Easy Judge setup and management.
- Have an existing LLM Judge? Import and reuse it as is. Utilize it efficiently through evaluation cycle/sampling settings!
- No LLM Judge? Quickly define one using AI.
- Judge projects and evaluation history aren't scattered - view, apply, and manage everything in one console.
4. How to use it? 💁♀️
Step 1Prepare data for evaluation (Dataset, Langfuse)
Step 2Prepare evaluation criteria (Evaluator)
Step 3Evaluate (Evaluation)
🎉 Check results
Step 1 Prepare data for evaluation. Both direct upload and Langfuse integration are supported.
Step 1 Prepare data for evaluation. Both direct upload and Langfuse integration are supported.Option 1️⃣ Direct upload to GIP - Great for testing and improving evaluation criteria with a fixed dataset.
-
Create a dataset.
-
Path: Platform > Storage > Datasets > Create
-
-
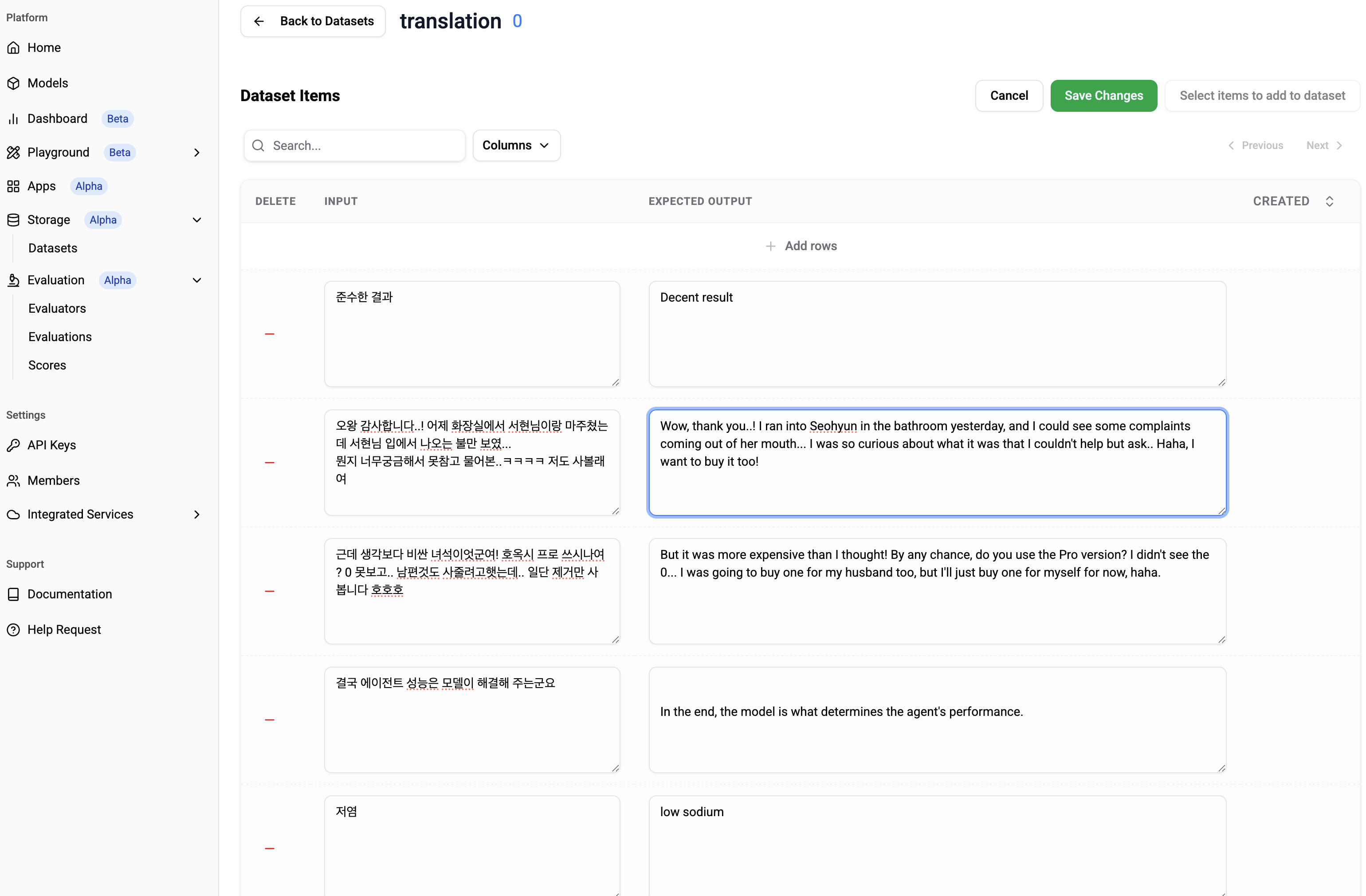
Add data to the dataset.
-
Path: Platform > Storage > Datasets > Dataset > Edit
-
Option 2️⃣ Langfuse integration - Great for periodic evaluation with data streamed to Langfuse.
-
Connect Langfuse
-
Path: Settings > Integrated Services > Credentials
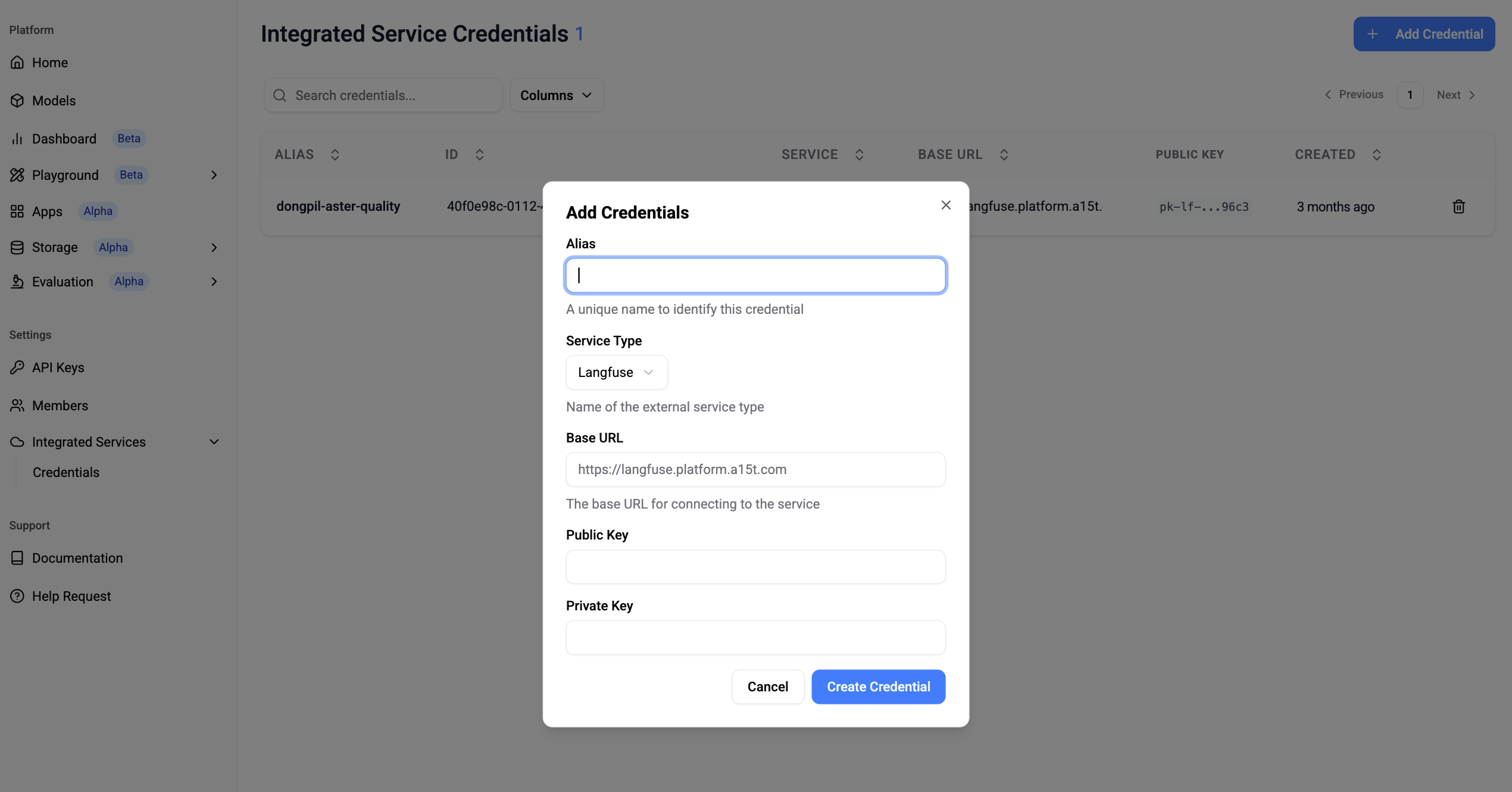
✅ You can find this in Langfuse > Project > Settings > API Keys.
-
Step 2 Prepare evaluation criteria.
Step 2 Prepare evaluation criteria.-
Path: Platform > Evaluation > Evaluators > Create
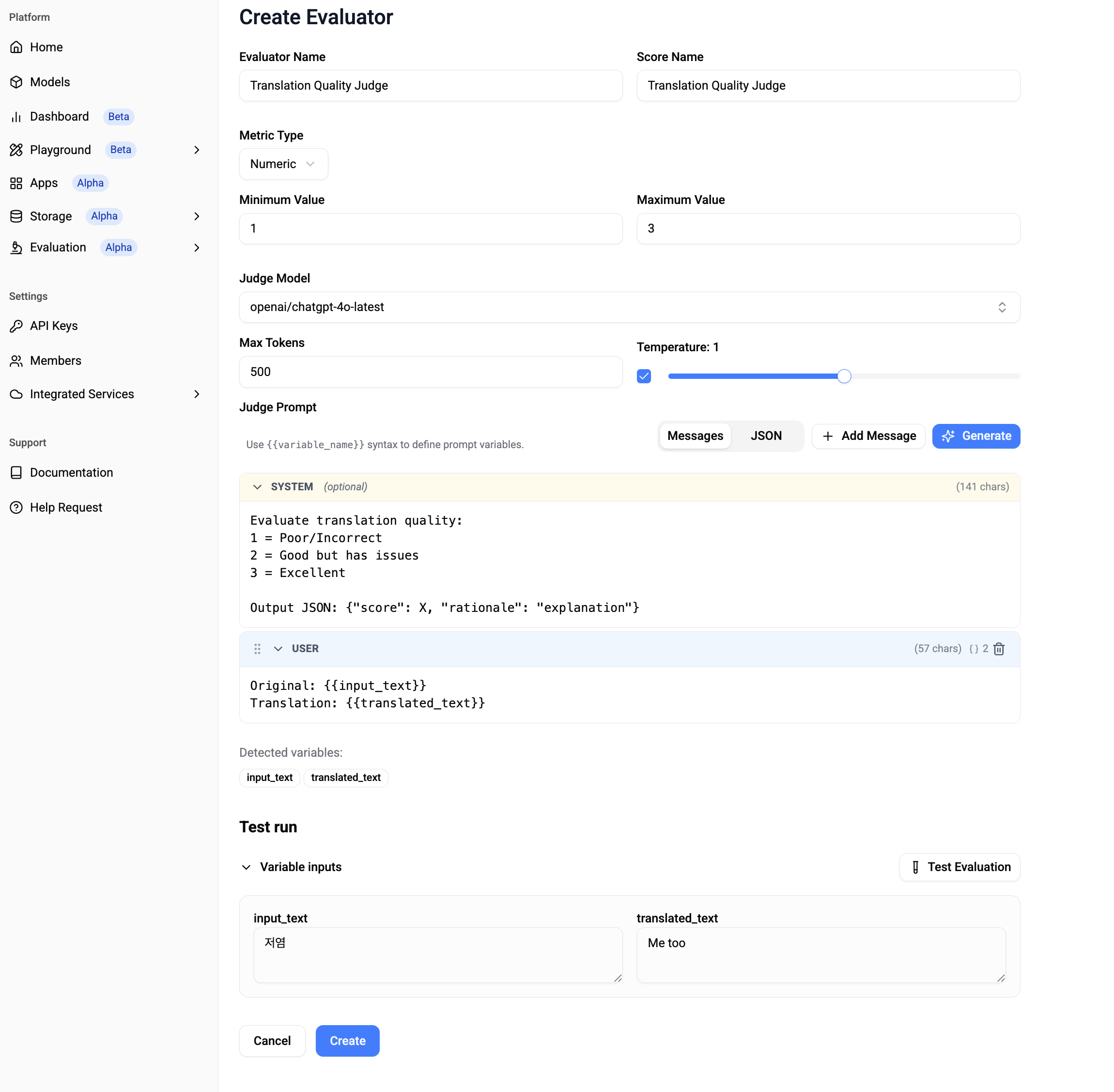
✅ Three types of evaluation criteria (Metric Type) are supported: Numeric, Boolean, and Category. Categories can be specified directly.
✅ If it's difficult to describe evaluation criteria, you can get AI assistance (Judge Prompt > Generate).
✅ Before saving the evaluation criteria, test it (Test Evaluation) and gradually improve the Evaluator by modifying the Prompt and Judge Model.
Step 3 Evaluate.
Step 3 Evaluate.-
Path: Platform > Evaluation > Evaluations > Create
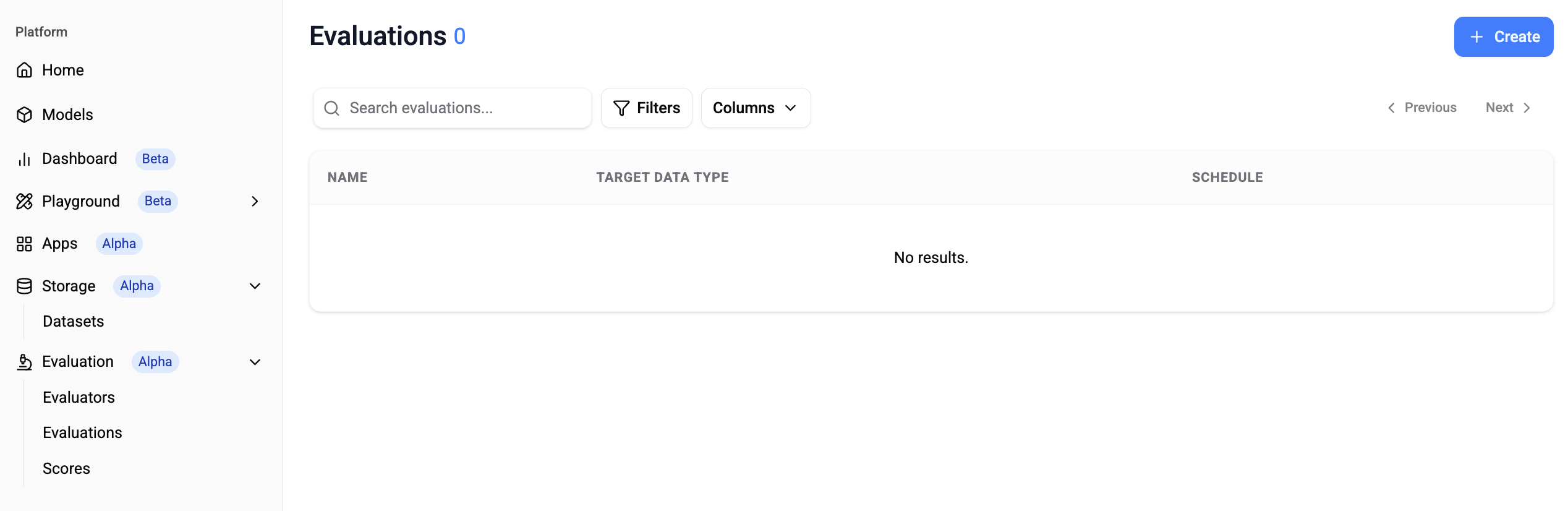
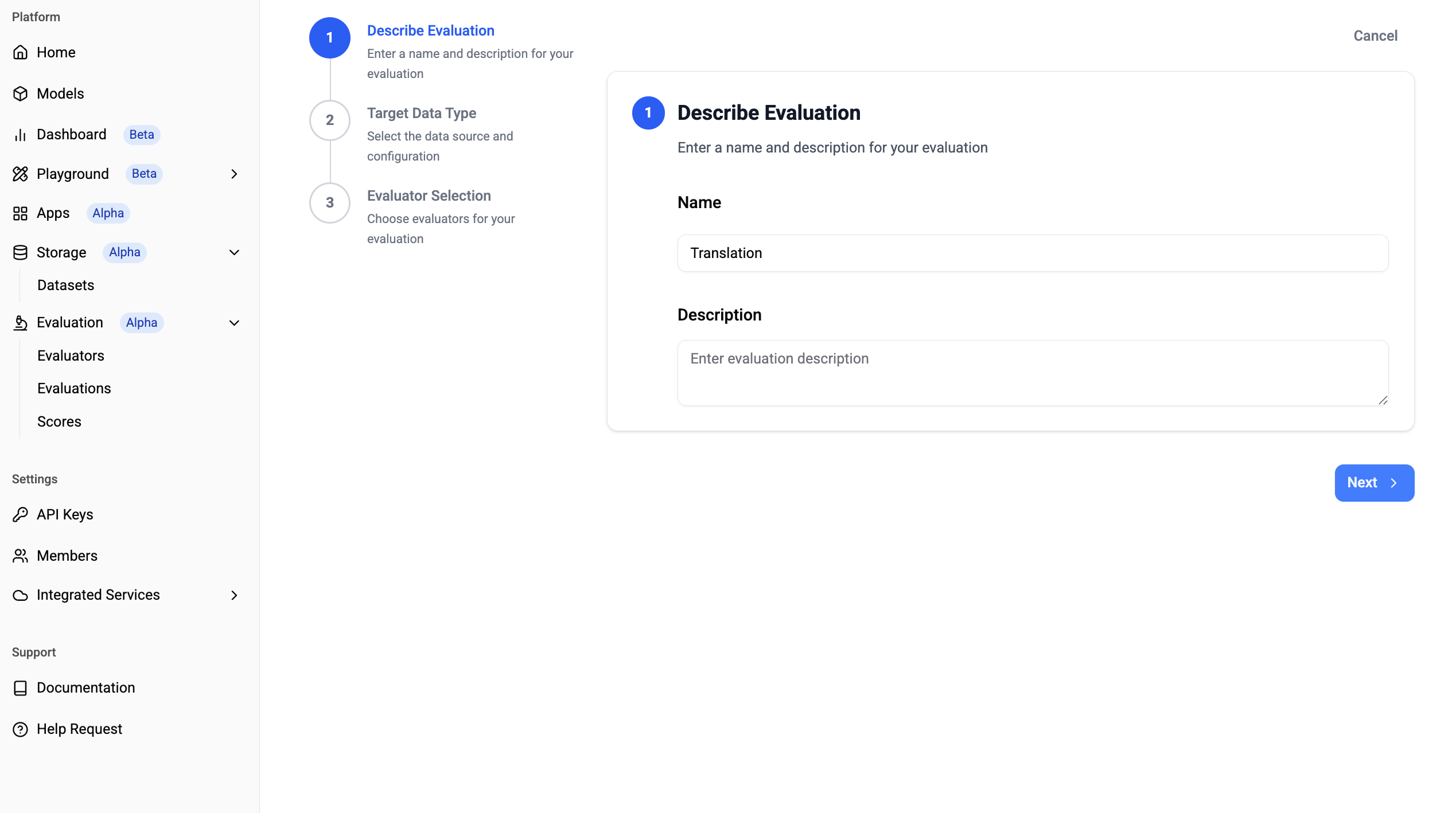
✅ Target Data Type
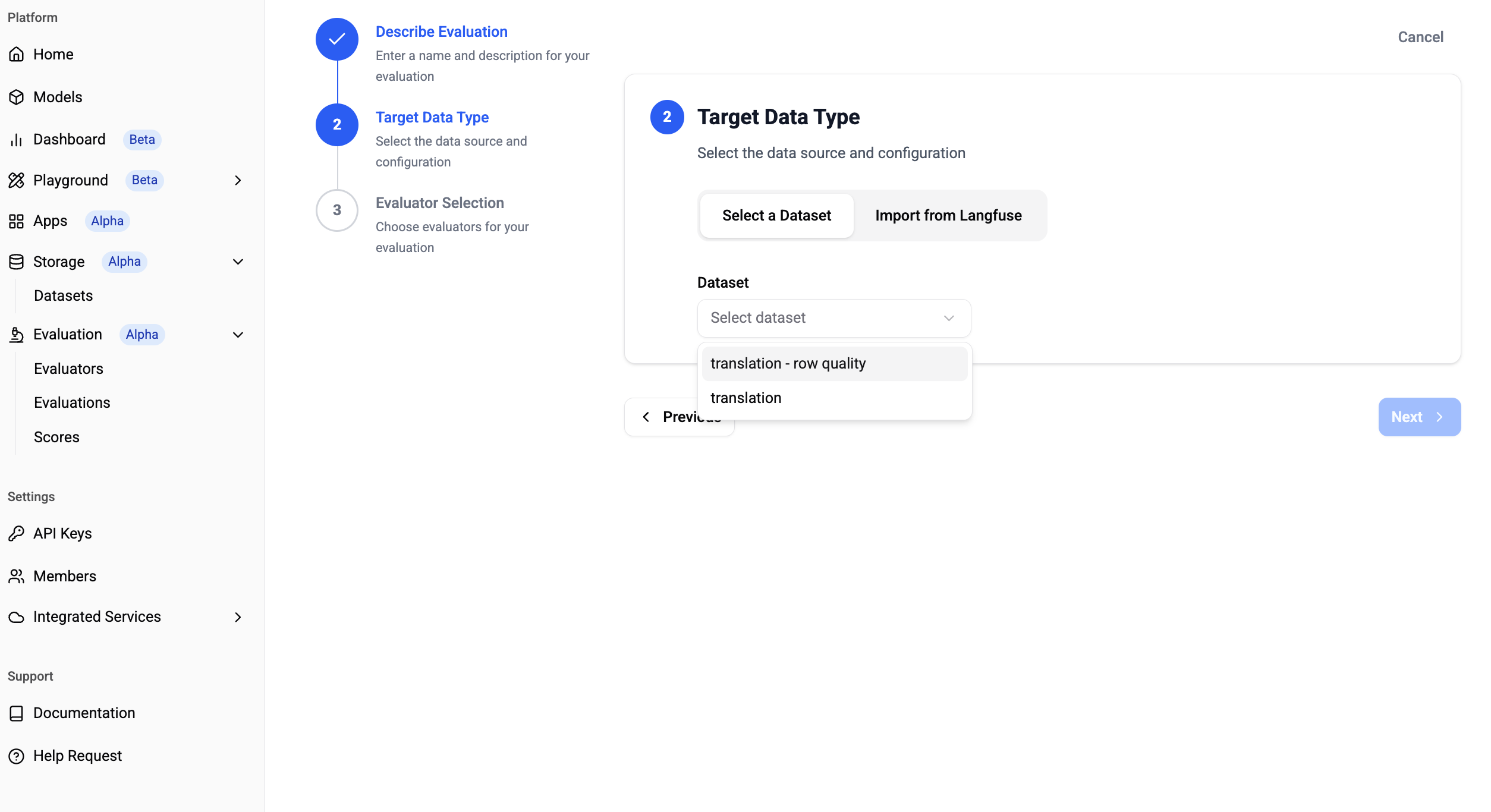
You can specify the dataset created in Step 1 (Select a Dataset) or import data using Langfuse API Key (Import from Langfuse).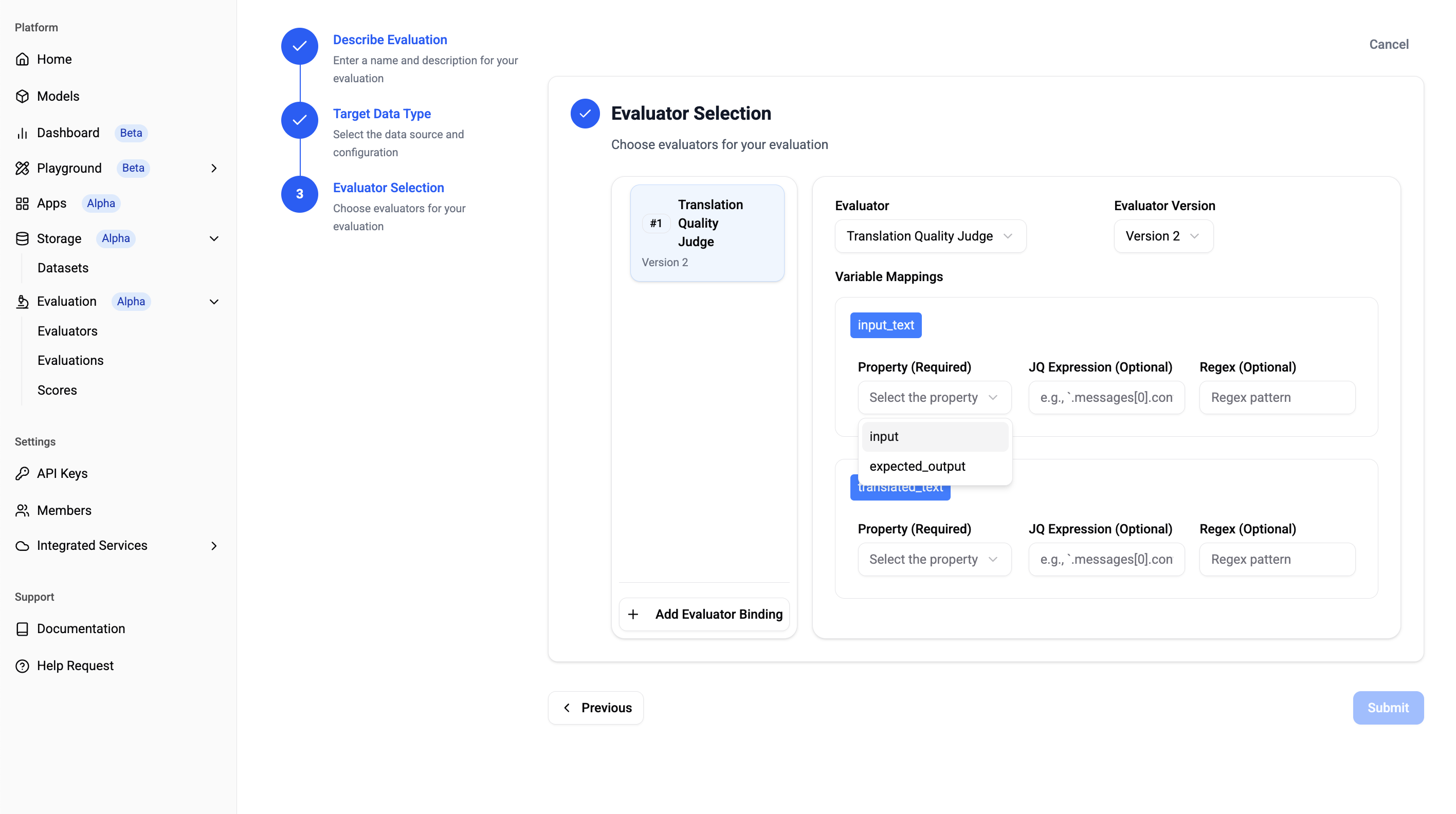
✅ Evaluator Selection
You can specify the evaluation criteria created in Step 2.
You can extract only part of the data using JQ Expression or Regex. -
Path: Single Run
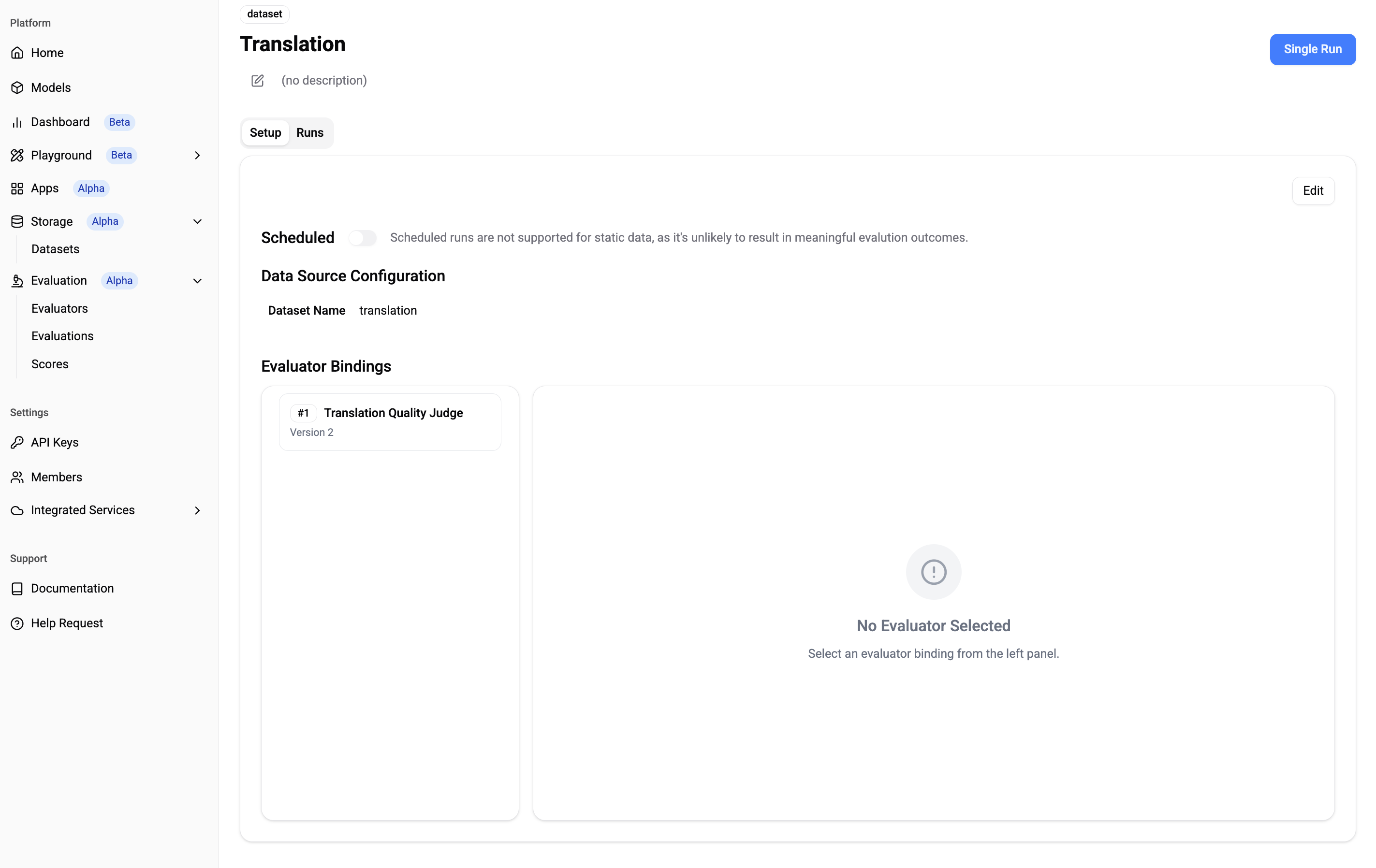
✅ Single Run
Run the evaluation!
🎉 Check Results
🎉 Check Results-
Path: Platform > Evaluation > Evaluations > Runs > Overview / Scores
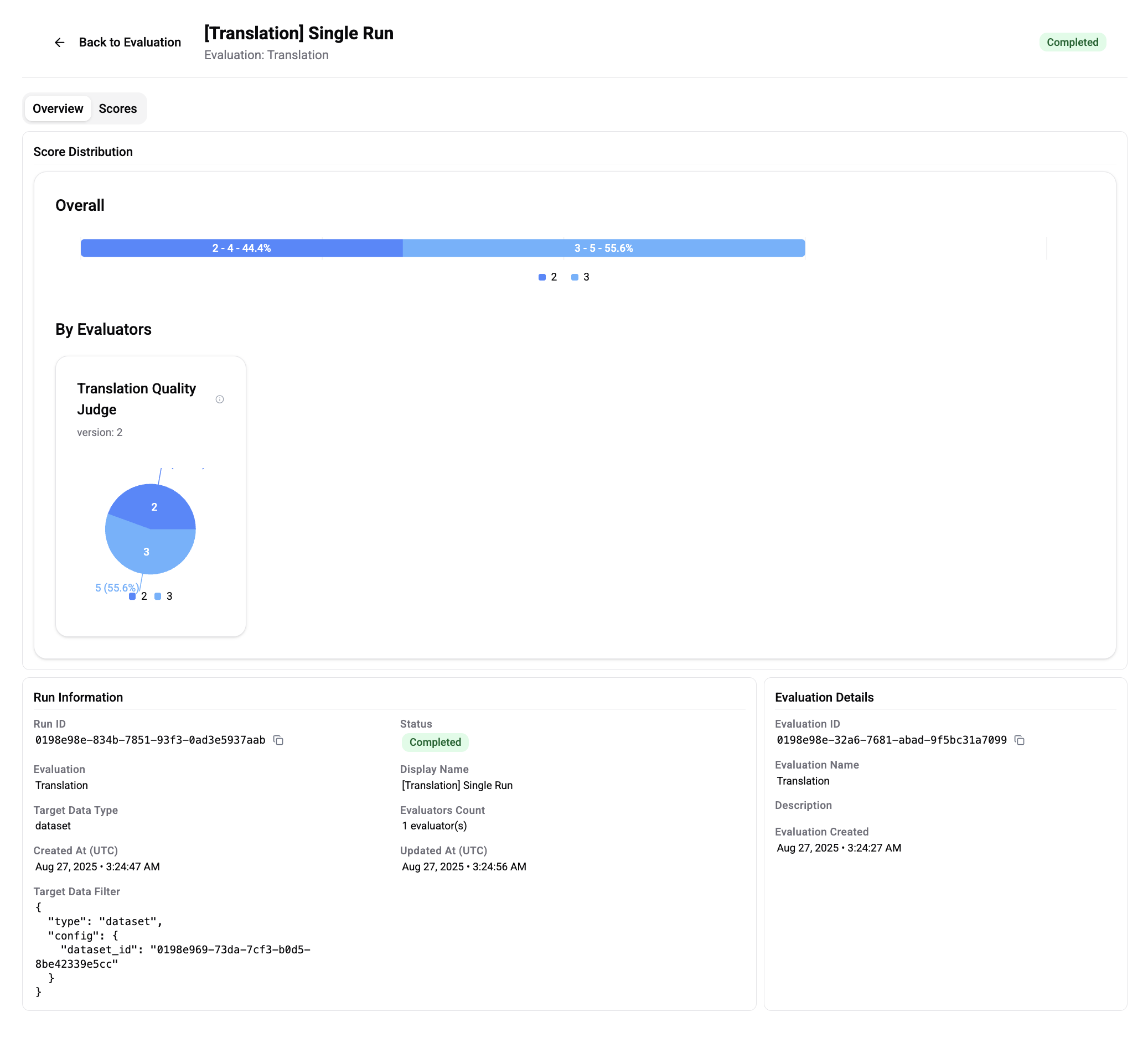
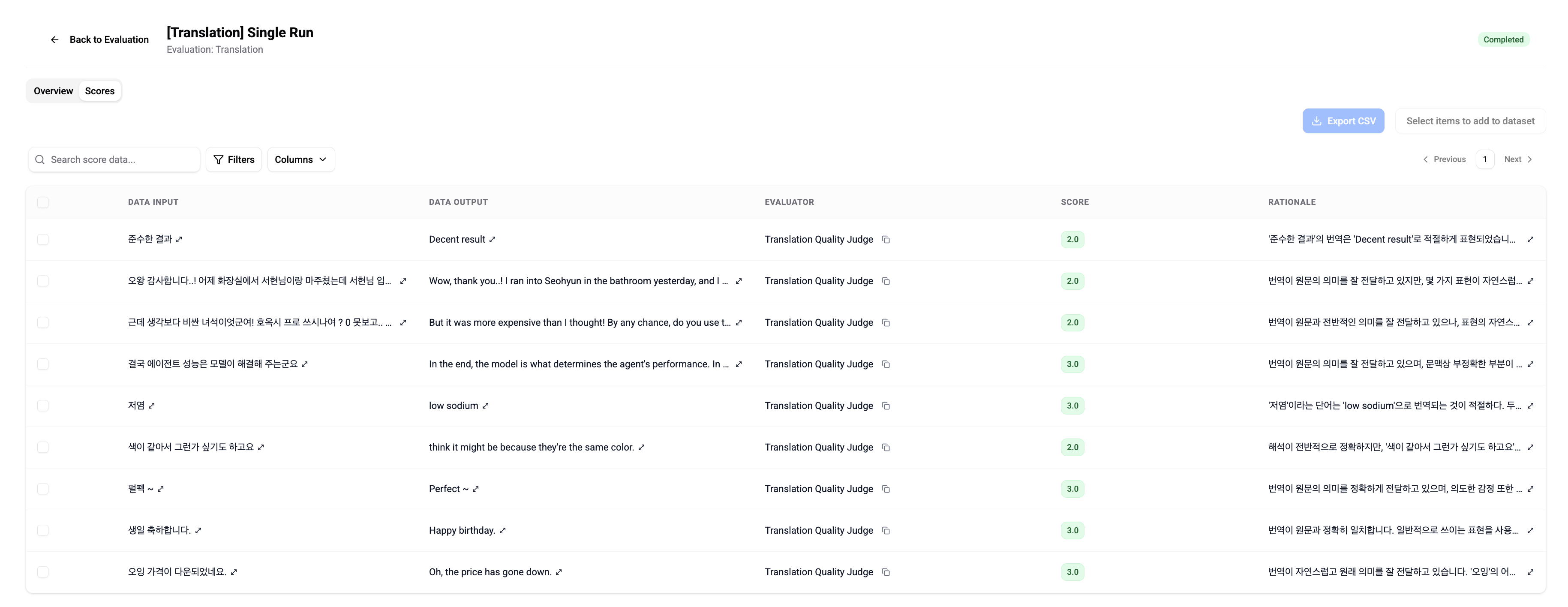
✅ Check evaluation results in Overview and Scores, and share the link with your team.
Anyone with Workspace permissions can view reports and collaborate together.
5. FAQ ❓
- Where can I find the API guide?
- You can check it here.
Updated 3 months ago